大模型技术仍然在不断更新,能让人感知到幻觉程度也在逐渐降低。但在它被投入到具体的领域和使用场景时,幻觉效应仍在发生,在这篇文章里我们会谈到的它在软件开发领域的应用。
软件行业苦降本增效久已。蔓延开去的开发周期,遥遥无望的上线时间,以及不断冒起的缺陷,怎么看都配不上这支精兵强将的队伍。生成式AI 似乎带来了曙光,它的表现让人耳目一新,不少人会这么想。它能自动生成代码,成本低,可重复,即抛的能力像云上的资源,这段代码不合适?扔掉好了,重新生成一段。很自然就会想到,是不是也不需要这么多精兵强将了,程序员们也很担心这一点。

生成式 AI 回答我们的问题时,偶尔会抛出个煞有介事的答案,但如果你稍作检索,就会发现这个答案徒有其表:不是查无此言,就是一派胡言,这与人工智能的威名不符。这即所谓生成式 AI 的幻觉,hallucination——因为没有真实可靠的语料,它自作主张拼凑了一个假的回答。
大模型技术仍然在不断更新,能让人感知到幻觉程度也在逐渐降低。但在它被投入到具体的领域和使用场景时,幻觉效应仍在发生,在这篇文章里我们会谈到的它在软件开发领域的应用。
幻觉一:更快的速度
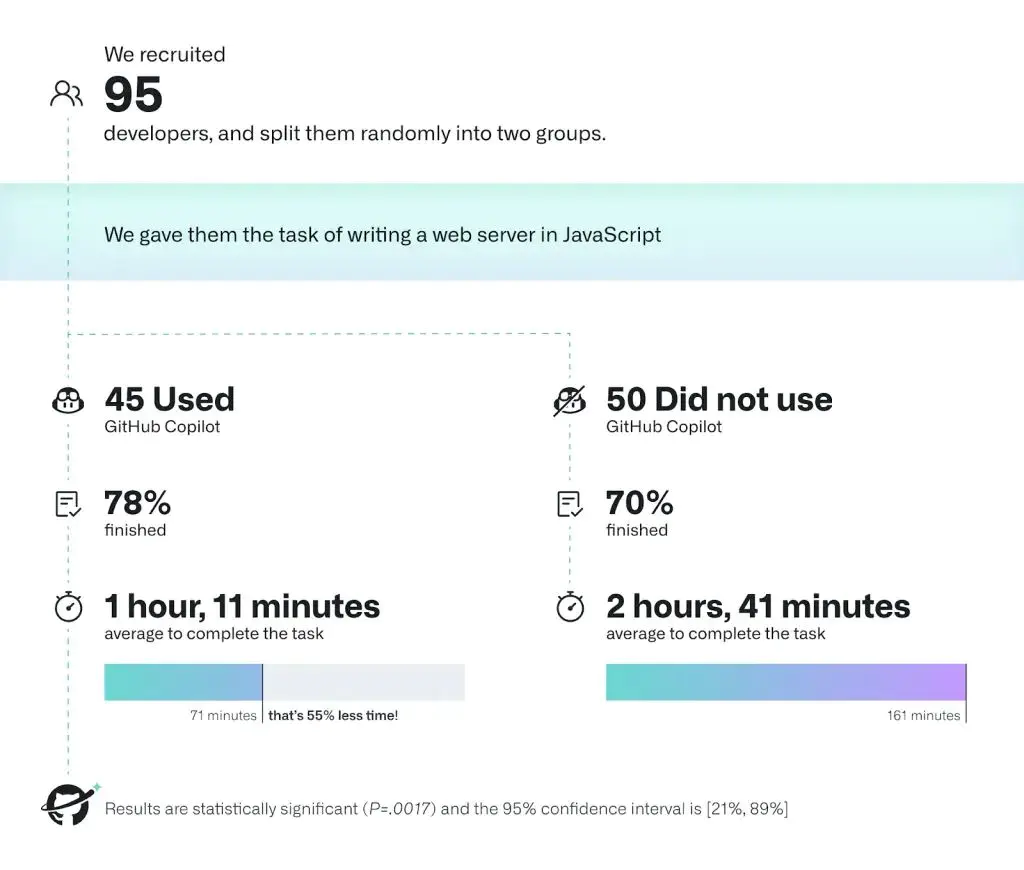
不同的软件工具厂商都在迭代更新自己的代码助手产品,最著名的是 GitHub 的 Copilot,他们宣称,可以加快程序员完成任务的速度达 55%以上,那些清丽迅捷的演示视频看起来也如飞一般。
(图片来源:https://github.blog/2022-09-07-research-quantifying-github-copilots-impact-on-developer-productivity-and-happiness/)
但这是否意味着软件的交付进度可以加快 50%?
那些作为演示的代码是可疑的,更多程序员在自己的项目中采用Copilot的反馈似乎也表明,提速基本只会出现在一些常用的功能实现上。数组的排序,数据结构的初始化,要不然就是一些再简单不过的模板代码。
可重复的工具代码交由 AI 也就罢了。但对于一个开发中的软件而言,有多少类似的代码需要重复开发呢,这恐怕是值得讨论的。遑论多数时候,它们只需要一次成型,封装待用。
还有数量相当可观的业务代码,程序员会以怎样的速度来进行?你可以把足够数量的业务代码交由 AI 来生成,但是否安全恐怕是一个更大的问题。
这里还有两个问题值得关注。
一是程序员对AI 提供代码的选择。
AI 如此容易提供多套方法的实现,程序员难免要尝试从中找出最优的选项。
这个好?还是那个好?咦,竟然有五种不同的实现。需要先读懂每一种代码的实现,再切换到下一种。这个实现的方法很优雅,但可惜单元测试失败了。换下一个。
程序员的好奇心被代码助手充分搅动。心猿意马,线性的思维习惯碎落一地。程序员遗忘的不只是开发纪律,还有时间。
二是软件自有生命周期。
很显然,轮到程序员开始编写代码,很多事情已经发生,而更多的事情还会继续发生,直到系统上线。这些事情包括但不限于:收集需求,理解需求(从需求说明到用户故事),测试,维护基础设施,以及那些层出不穷的修复工作。
我的意思是说,即便AI 帮助程序员写得再快,这个阶段也只是软件生命周期中的一部分而已。早有相关的数据统计,程序员日常的工作,只有 30%的时间是在编写代码,而更多的时间是在尝试理解他们要实现什么功能,以及设计和学习新技能上。

(图片来源:https://github.blog/2023-06-13-survey-reveals-ais-impact-on-the-developer-experience/)
幻觉二:更少的 Bug
人编写的代码难免存在缺陷,这是软件质量的基本共识。而且似乎越有经验的程序员,越容易生产出隐晦的问题,要过了很久才会被发觉。线上问题更让人提心吊胆,但这样的担心很难避免。
AI 生成的代码,听起来也很高级,是不是会带来足够完美的结果?很可惜,答案可能会让人失望。
生成式 AI 背后的大模型,以互联网上大量的语料作为数据来源,尽管大模型技术一直在改善,但网络上已经现实存在的带有偏见的数据量十分可观。这也包括大量饱含缺陷的代码。
这意味着程序员在代码助手中精挑细选的代码,也可能存有缺陷。因为这段有缺陷的代码,可能来自地球另一端的某个人,只是恰巧成为了地球这一端的选择。
要命的是,生成式 AI 有放大器(amplify)的功效。简单来说,就是如果程序员采用了存有缺陷的生成代码,Copilot 会记录这样的行为,在接下来类似的场景,会继续建议有缺陷或差不多的代码。AI 并不能读懂这样的代码,它只是被鼓励继续提供。我们可以预想最后的结果。

(prompt:A programmer is sitting at a computer desk, looking confused and frustrated. The computer screen shows a code editor with a pop-up window of GitHub Copilot suggesting incorrect code, symbolized by red error indicators and crossed-out lines in the code. The programmer is scratching their head, surrounded by crumpled paper, indicating multiple failed attempts. The scene conveys a sense of challenge and confusion due to the reliance on incorrect AI-generated code suggestions, leading to quality issues in software development. The room is cluttered, reflecting the chaotic situation. )
程序员要严守团队的开发纪律,保持统一的代码规范,因为这样别人才能读懂,也意味着更容易发现潜在问题并修复它。但代码助手提供的不同样貌的代码,似乎也提供了更多的混乱。
代码有缺陷,只是软件最后会爆出难以挽回的问题来源之一,甚至是很少的一部分。构建软件的过程,其实是知识生产和创造的过程。在软件生命周期不同阶段加入进来的各角色,共同理解和分析软件的需求,然后转换其为代码,也在团队和人员更替的过程中,传递这些表面为需求和代码实则为知识的信息。
但通常,知识会衰减,知识资产的传递会不可避免地出现差池。读不懂代码,无法持续更新文档,整个团队又被替换,还有更多可能性。这些才是软件不断产生 Bug 和问题的原因所在。人工智能并未能解决这些软件工程中棘手的问题,至少现在看短时间内做不到。
幻觉三:更少的人
AI 的代码助手看起来确实像见多识广的程序员。甚至有人愿意把它当成结对编程实践的伙伴。用人成本一直是 IT 团队头疼的问题,好手太贵,合适的人招不到,从头去培养熟练的程序员又需要太久时间。有了人工智能和代码助手的加持,是否意味着可以缩编快一半的人?
AI 和代码助手不仅无法提供上述的速度快和质量高保障外,也期待使用者要有足够经验的程序员才好,才能尽可发挥它该有的优势。这位有经验的程序员,需要有能力判断代码的优劣,判定对已有生产代码的影响,还需要有精心调整提示词的耐心和技巧。
在这篇文章里,作者讲述了她在使用代码助手时诸多要留意的问题,还有你能看到的她缜密的内心戏。因为代码助手带来的不确定性,可能会引起两类风险,一是影响到代码的质量,二是浪费时间。这里其实显示的是一位足够资深的程序员的自省能力。
也只有这样,代码助手才可以心安理得扮演见多识广的新手,而经验程序员充当守门员,她才是那个负责提交代码的人。这样说来,AI 改变的是编程体验。

(图片来源:https://martinfowler.com/articles/exploring-gen-ai.html,作者把代码助手想象成一个着急帮忙、固执、说话清楚但缺乏经验的角色,于是用 AI 画出了这个卡通形象)
AI 和代码助手在解决简单重复性问题上,效果显著。但在构建软件的过程中,有更多需要人和专业经验的场景,来解决复杂的问题。比如软件系统日益增加的架构复杂度和范围,应付市场和业务侧的需求,跨角色之间的沟通和协作,还有那些更加时髦的涉及代码伦理和安全的问题。
虽然判断程序员是否足够专业和熟练,不像数数那样一目了然,但我们也可以说,引入AI 和代码助手然后减员开发团队,能带来的成效是不确定的,目前看弊大于利。
写在最后
生成式 AI 的本质是模式转换,从文字的一种形式,转换成另一种形式,高级的代码助手的能力也不出其右。如果把涉足软件构建的 AI 代码助手,认为是解决诸多软件工程难题的妙方,我们恐怕只是把复杂的问题想得过于简单。
写到这里,我们一直在谈什么呢。
我们在谈的其实是,在软件开发上投资 AI 的成效该如何衡量。投资 AI 并不是简单如购买代码助手的 License,然后就可以坐享降本增效。不断询问“我们要如何衡量投资 AI 和代码助手的效果?”,不如询问“我们到底要衡量什么?”。从DORA 定义的四个关键指标开始,是个明智的选择,它们是变更前置时间、部署频率、平均恢复时间 (MTTR) 和变更失败率。
下面是建议的一些基本衡量原则:
- 衡量团队效率,而不是个人绩效。
- 衡量成效而不是产出。
- 查看随时间推移的趋势,而不是比较不同团队的绝对值。
- 用仪表板上的数据开启对话,而不是就此结束。
- 衡量有用的东西,而不是容易衡量的东西。
责任编辑:山木
作者:张凯峰
来源:Thoughtworks洞见